via youtube.com
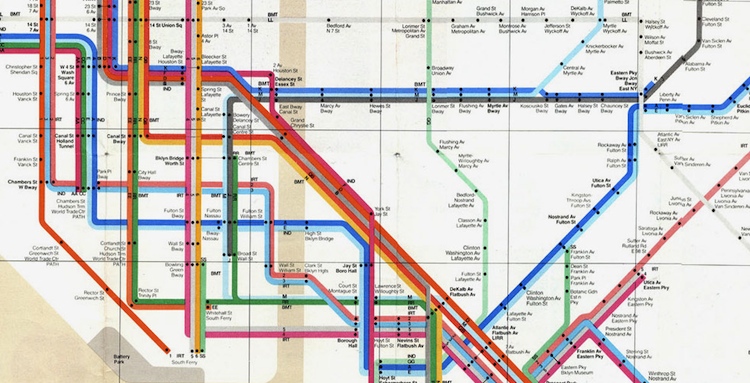
Alexander Chen used HTML5 and Massimo Vignelli's famous subway map to turn NYC's mass transit system into a playable musical instrument.Manhattan denizens sometimes describe the sounds of the subway as the city's incidental music. Now programmer/designer Alexander Chen has created a more soothing version with MTA.me, an interactive NYC subway map-turned-musical-instrument that uses transit lines as its strings.
Chen, who works at Google Creative Lab, used HTML5 to code MTA.me's behavior: not only do crossing train lines "pluck" each other's strings, you can do the same thing with your mouse. And as for the map itself, Chen chose the classic/infamous Massimo Vignelli design as his template.
A detail from Vignelli's 1972 NYC subway map.
The choice makes sense: the "strings" in Chen's instrument need to be taut and straight, and Vignelli's ruthlessly rectilinear design (inspired by the London Tube map, which was itself inspired by electrical engineering diagrams) provides the necessary visual tension for "plucking."
But MTA.me isn't just design-homage in a vacuum: using the real MTA's public API, Chen's creation polls real-time train departures and arrivals to spawn its animation. The map then accelerates through a 24-hour loop of subway activity, generating music with just enough randomness to be interesting but not distracting. The effect is not unlike that of Pulsate, another browser-based musical interactive piece we raved about.
Other subtle-but-delightful design touches: the length of the train line dynamically determines its pitch when plucked, and the white background fades to black as the 24-hour train cycle makes its way from day to night. Chen even added historical easter eggs for eagle-eyed transit buffs: "The 8 train, or the Third Ave El, was shut down in 1973. The former K train was merged into other routes. I decided to run these ghost trains between 12am-2am," he says in his blog.
As an interactive portrait-in-code of the most famous mass transit system in the world, MTA.me excels. And it's a helluva lot more pleasant to listen to than the screeching sounds of the 4 train at Union Square.
Google appears to be testing display ads in Gmail. I discovered the following image ad in my own Gmail account this morning, and Google has since confirmed a test.
Image ads have made their way into paid search on Google.com and various other properties on Google. But this was really jarring for me to encounter. It’s the only such ad I saw (next to an email from a clothing retailer in my inbox) after purposely looking for others.
I’m sure it’s a test to see how users react and what the response rates are. Gmail is formally a part of the “Google Display Network“:
Your text, image, rich media, and video ads can appear across YouTube, Google properties such as Google Finance, Gmail, Google Maps, Blogger, as well as over one million Web, video, gaming, and mobile display partners.I’m not sure how long this test has been running; it’s the first time I’ve seen it and I use Gmail as my primary email address.
Postscript: A Google spokesperson provided the following comment:
We’re always trying out new ad formats and placements in Gmail, and we recently started experimenting with image ads on messages with heavy image content.
A spectre is haunting Mountain View. No, not bed bugs: bit rot. Google is in serious decline.
I don’t see how they can deny it. They have famously always been a data-driven organization, and the data is compelling. Business Insider’s list of the 15 biggest tech flops of 2010 cited no fewer than four from Google: Buzz, Wave, Google TV, and the Nexus One. Bizarre errors have erupted in Google Maps. Many of its best engineers are leaving. Influential luminaries like Vivek Wadhwa, Jeff Atwood, Marco Arment and Paul Kedrosky (way ahead of the curve) say their core search service is much degraded from its glory years, and the numbers bear this out; after years of unassailable dominance, Google’s search-market share is diminishing—it dropped an eyebrow-raising 1.2% just from October to November—while Microsoft’s Bing, whose UI Google tried and embarrassingly failed to copy earlier this year, is on the rise.
Even their money fount, AdWords, is problematic. An illustrative anecdote: I recently experimented with a $100 free certificate for my own pet app, and found my ad got stuck “In Review” indefinitely. According to users on AdWords’ discussion boards, this is common, and the only way to fix it is to file a help request. I did, and the problem was soon repaired—but what happened to the speedy algorithmic solutions for which Google is famous?
The general tone on the AdWords forums is exactly like that on those devoted to the other Google service I use a lot, App Engine: users on both frequently complain about the way Google neglects and/or outright ignores them. I like App Engine a lot, but it’s prone to sporadic bursts of inexplicable behaviour, and some developers are abandoning it because of Google’s perceived reluctance or inability to fix its bugs and quirks. Another example: a bug in Android’s default SMS app which sent text messages to incorrect recipients festered for six months until a spate of high-profile coverage finally forced them to fix it. How can they neglect problems like that in their only big hit of the last five years? Never mind don’t be evil—what happened to pay attention?
Once upon a time, Google was the coolest place for a techie to work. Not any more. While I can’t quantify this, I’m confident that most engineers will agree: somehow, over the last 18 months, their aura has faded and their halo has fallen. Once their arrogance was intimidating and awesome. Now it just seems clueless.
I feel a little bad being this critical, because I am—or was—a giant Google fan. I admire their China stance, and the way that they innovate like crazy and constantly take chances, not all of which pay off. I had an Android before Android was cool. But this is no mere losing streak; this is systematic degradation. They seem to be rotting from the inside out.
What happened? The same cancer that sickened Microsoft: bureaucracy. A recent NYT article claims that “the bleak reality of corporate growth” is that “efficiencies of scale are almost always outweighed by the burdens of bureaucracy.” A famous (and brilliant) essay by Moishe Lettvin, a former MS employee, explains why Windows Vista was such a turkey: at the time, every decision—and every line of code—had to filter through seven layers of management.
My sources tell me that since then Microsoft has become much more efficient, and their recent successes—XBox, Kinect, Windows 7, Windows Phone, Bing—testify to this. Kudos to them. Can Google do the same? Let’s hope so. But their situation is more difficult and dangerous: they could conceivably lose 90% of their business in the space of a few months, if a qualitatively better search engine comes along. That’s not likely to happen, but it could . . . and I’m almost beginning to hope that it does.
It’s not like they’re Yahoo!, halfway past the point of no return. Google is still a giant money machine full of brilliant engineers. Google Voice could be huge. If the rumors of their super-secret augmented-reality app are true, they have another hit in the wings. Even their self-driving cars make strategic sense to me. Still, the trajectory is clear; they’re in decline. They seem to have finally stopped believing their own press releases and realized that they have a problem—but is it too late? Has Google grown too big to succeed? I fear that the answer is yes
A lot of content on the Web today is syndicated across multiple sites. For Google News, that's a problem, as the service has to determine which one of these sources to pick as a headline. Today, Google introduced two new metatags that allow publishers to give "credit where credit is due," as the company puts it, and highlight original sources and indicate when something is a syndicated copy. Google will use this information to rank stories on Google News.
The two new tags that Google introduced today are syndication-source and original-source. The syndication-source tag can be used to indicate the location of the original story. The original-source tag should be used to highlight the URL of "the first article to report a story." A story that uses material from a variety of original sources can include more than one original-source tags to point to these. Both of these tags can also point to the current page URL, so publishers can call attention to their own original reporting. You can find more details for how to implement these tags on your site here.
For now, Google still calls this an experiment is only using the syndication-source tag in its rankings to distinguish among groups of duplicate articles. The original-source is "only being studied" and doesn't factor into Google's rankings yet.
It is worth noting that the hNews microformat, which was developed by the Associated Press and the Media Standards Trust, already offers a similar functionality, including a tag for identifying the originating organization for a news story. According to Google, though, "the options currently in existence addressed different use cases or were insufficient to achieve our goals."
Can You Trust the Internet?
The problem with this system is that it is based on trust, as Search Engine Land's Matt McGee rightly notes. Nobody can stop a spammer from marking unlicensed copies of a story as original sources, for example. In it's FAQ for these tags, Google says that it will look out for potential abuse and either ignore the source tags from offending sites or completely remove them from Google News.
Read/Write Web today reports on an effort by Google to encourage web publishers to specify whether their content is original or syndicated. The problem focused on by Read/Write Web is that of Google News and how Google attributes the author of a story when it crawls the many syndicated copies out there:
The two new tags that Google introduced today are syndication-source and original-source. The syndication-source tag can be used to indicate the location of the original story. The original-source tag should be used to highlight the URL of “the first article to report a story.” A story that uses material from a variety of original sources can include more than one original-source tags to point to these. Both of these tags can also point to the current page URL, so publishers can call attention to their own original reporting. You can find more details for how to implement these tags on your site here.
For now, Google still calls this an experiment is only using the syndication-source tag in its rankings to distinguish among groups of duplicate articles. The original-source is “only being studied” and doesn’t factor into Google’s rankings yet.
Of course, duplicate listing content is a problem in the real estate space as well. Here are several questions:
- Should listing syndicators like ThreeWide (now owned Move, Inc.) and Point2 specify the original-source?
- What should be the original source?
- Does this also apply to IDX offerings?
- If IDX listings contain the original-source tag and point it back to the listing broker, should this reduce the need to disclose the broker name on summary reports as apparently is the case now for franchise sites using IDX listings?
- What other implications or uses do you see for these tags?
Categorized under: IDX,Syndication
In 2005, at Google, we acquired an analytics company called Urchin. Urchin, now Google Analytics, was integrated into Google Adwords and was meant to allow advertisers to track conversions across all online sources. There were and are some challenges however with the accuracy of some of the reports. Here are a few examples:
- Javascript Code was added incorrectly on advertiser’s site
- Users clear their cookies and can’t be tracked
- Ad filtering programs can block the script
- Script could slow down site causing a higher user abandonment rate
All of these issues could lead to inaccurate reports where the marketer thinks one source or various keywords are performing poorly. Tracking conversion is an essential part of any marketing program within any industry. However, making marketing decisions based on bad data could hurt marketing performance.
Specifically in the apartment industry, leases, many times are attributed to the wrong source. At a recent NMHC event, the panel warned:
that properly sourcing leads is a big problem in the industry. One analysis showed that 70% of leases were attributed to the wrong source.
As the apartment industry becomes more sophisticated on what leads are converting into leases by using third party lead-to-lease services, I am seeing many of the same data tracking errors that I saw at Google. Recently, we compared internal lead data to multiple client lease data and found a 10-12X discrepancy in what leads actually turned into leases and what their third-party data was telling them.
Here are a few apartment marketing tracking challenges I see:
- Dead tracking numbers
- Surprisingly, sometimes marketers forget to change out tracking numbers and potential residents go to a dead number
- Improper parsing of email data
- In some cases, parsing of name, email, phone-number may not be parsed accurately from the third-party
- Manual over-ride of source data
- Psychologically, we tend to favor sources that make us look better. One REIT shared with us that walk-ins and “Internet Other” dropped 50% when they started to track via a call center.
- Revenue Attribution
- Who should receive the lease attribution? The first source, middle source, last source, or all sources?
- The Network Effect
- More and more leads are coming from the long-tail of sites. “Internet Other” option is becoming a larger portion of lease sources.
- The Human Element
- Lack of accurate lead collection data at the community level may lead to larger discrepancies.
- Different phone and or email addresses presented when signing the lease
- Many potential residents search while at work. Did their work email and phone show in the lead reports but their home information show in the guest card / lease software?
As an industry, we are getting closer to accurately quantifying apartment advertising spend but we are a long way to perfection. Would love feedback, thoughts, suggestions on how we as an industry could improve the accuracy of this data.
|
Google unveiled it's new Books Ngram Viewer last week, which tracks words indexed by Google Scholar, allowing any user to potentially trace cultural trends through archived literature. The above n-gram tracks the prevalence of the words "television," "radio," "newspaper," and "Internet," with relatively predictable results as media has morphed throughout the past century. Though the data trends are of course limited to Google's own "canon" (of indexed books), the results that CNET calls A Time Machine For Wordplay are utterly fascinating. Profound shifts in American philosophy over the past two centuries can be traced to the prevalence of usage of the words "Liberty" vs. "Freedom," which I found in Alexis Madrigal's article in The Atlantic. Also amusing is the rise of Vampires, Werewolves and Zombies in recent Literature. |
|
|
|
Google now lets you filter sites by "reading level".
The internet used to be full of highbrow reading material, until broadband penetration exploded and everyone with a credit card managed to find his or her way onto the web. Finding your way back to the rarefied air that used to suffuse the 'net can be a slog, so Google has a new way to help you out: You can now sort sites by reading level.
(For those of you following along at home, under Google's 'advanced' search, simply switch on this option by hitting the dropdown next to "Reading level.")
The results are fascinating. Searching for any term, no matter how mundane, and then hitting the "advanced" link at the top strips away all the spam, random blogs and all the rest of the claptrap from the advertisers, hucksters and mouthbreathers.
This is only one of the varieties of elitism enabled by the new feature, which was created by statistically analyzing papers from Google Scholar and school teacher-rated webpages that are then compared to all the other sites in Google's index.
As pioneered by Adrien Chen of Gawker, by far the most interesting application of the tool is its ability to rate the overall level of material on any given site, simply by dropping site: [domain.com] into the search box.
By this measure, the hallowed halls of the publication you're reading now fare pretty well:

Not quite as well as some sites that share our audience:

But certainly better than certain other, decidedly middlebrow, publications:

It's when you turn to the scientific journals that the competition really heats up:

And the battle between traditional and open access publishing models takes on a new dimension:

(Just for reference, Here's how MIT itself performs)

And, much as I'm loathe to admit it, the smartest site on the Internet is...


Meanwhile, excluding sites aimed at children, here's the dumbest: